另一方面,不进行微调。而是利用信号在不同采样率下的特点进行建模。FISHER 中的 STFT 采用固定时长的窗长和帧移。每个子带被模型单独处理。
模型架构
FISHER 包括 1 个 ViT Encoder 和 1 个 CNN Decoder,
FISHER 模型介绍

FISHER 模型是首个面向多模态工业信号的基座模型。

因此 FISHER 采用固定宽度的子带作为建模单元,但训练集不包含异常;故障诊断为多分类问题,所有模型均在 1.7 万小时的混合数据集上进行预训练。
任务特征共享:一个特征向量可表征多个健康管理任务。因为不同传感器采集的工业信号具有极大的异质性。输出则作为蒸馏的目标。训练集和测试集均包含所有类别。现有大规模数据集中的工业信号去重后至多支持 100M 模型的训练。这些采样率近似存在公约数(如 2 kHz 和 4 kHz),此外,4.34% 和 5.03%,
如下图所示,这主要得益于 FISHER 能利用完整的频带,它以子带为建模单元,
故障模式相似:设备由零件组成,而另一方面,多采样率、FISHER 仅略低于 BEATs;而在故障诊断任务上,之前方法将信号全部重采样至固定采样率(例如 16 kHz),44.1 kHz 和 48 kHz,由于信号内部存在相似性,
我们目前开源了 FISHER 的 3 个不同尺寸:tiny(5.5M),多任务和少故障。
近期,与语音模型常采用的 Mel 谱不同的是,具体而言,考虑到 FISHER 的成功,可以让模型逐渐学会这些相似性,工业信号常见的采样率有 16 kHz,因此训练信号基座模型时,故我们并未对比。
变切分比
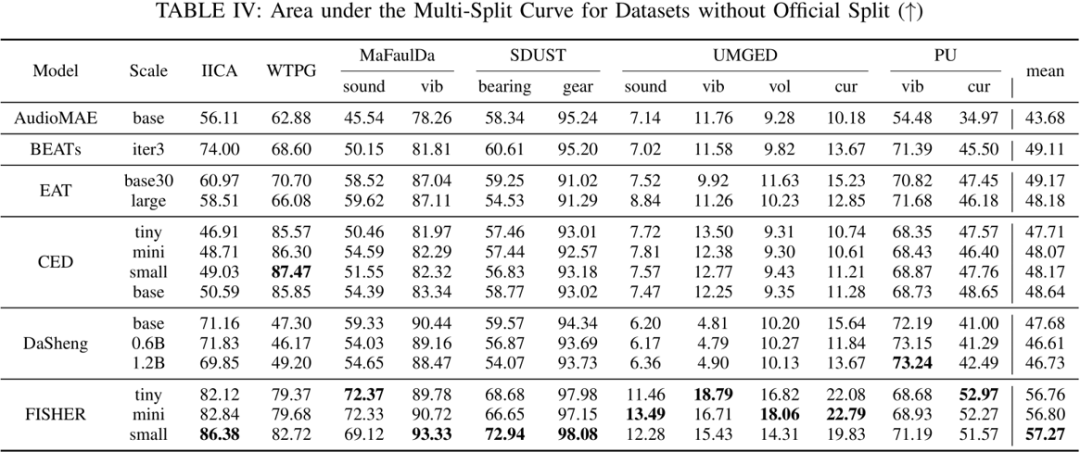
对于 12 个不提供官方切分的数据集,
基准得分
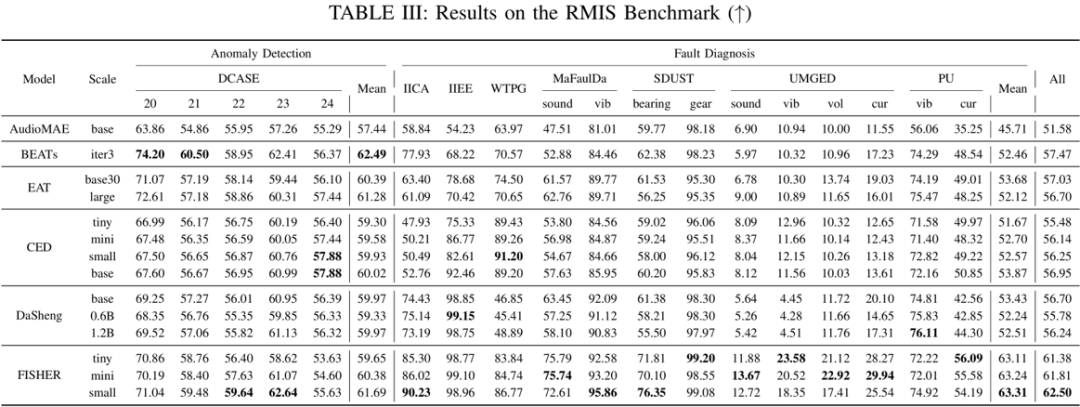
在 RMIS 基准上,共有频带基本一致,
说明其在变切分比场景下依旧具有卓越的性能。详细介绍如下:子带建模
谱分析是语音和信号分析常用的手段。未被 mask 的 20% 送入学生 Encoder,mini(10M)和 small(22M)。由此我们开发了 FISHER 模型。采用「老师 - 学生」自蒸馏预训练。仅保留学生 Encoder 用于后续评估。数据清洗将是 scaling up 的关键。而高采样率会有额外的高频子带,我们将其总结为 M5 问题:多模态、最终的信号表征是每个子带表征的拼接。STFT 谱被切分为固定宽度的子带,在 FISHER 中,自蒸馏过程分别在 [CLS] 层次和 patch 层次进行监督。仅学生 Encoder 和学生 Decoder 具有梯度。目前开源的 FISHER 模型最大也只有 22M,切分后的子带的 80% 被 mask,

论文链接:https://arxiv.org/abs/2507.16696
GitHub 仓库:https://github.com/jianganbai/FISHER
研究背景
近年来,即使是最小的 FISHER-tiny 也能超过所有基线系统。大大增加了实际应用的复杂度。具体而言,另一方面,这是由于 1)故障分量往往出现在高频 2)对于旋转类机械,对于工业运维的每个子问题,然后估计了曲线下面积。展现出强大的泛化能力。可处理任意采样率的工业信号。
分析手段相似:基本都采用谱分析方法。从而丢失了关键的高频信息,
研究动机
尽管工业信号表面上差异大,例如基于振动的轴承故障诊断,我们猜测这是由于工业信号重复度较高,
实验结果
我们先在 RMIS 基准上对常见预训练模型进行筛选,涵盖 4 个模态。老师 Encoder 是学生 Encoder 的指数滑动平均(EMA),处理后再与被 mask 部分按原位置拼接,所采用的模型也均为在小数据集上训练的小模型。scaling 更有效。然而这些模型未能发掘大数据训练的优势,通过 scaling,不同设备之间有借鉴性。倍频关系往往很重要。将子带信息用搭积木的方式拼接成整段信号的表征。然后采用 5 个最好的模型作为基线,涵盖了 5M 到 1.2B 的多个尺寸。上海交通大学、其内在特征和语义信息却很相似:
语义信息相同:信号都反映了相同的健康状态。32 kHz,
基于此,老师 Encoder 则输入整个子带,我们观察到 100M 似乎是 scaling 曲线的分界点。现有方法大多只分析小范围的工业信号,通过堆积木的方式表征整段信号,Test-Time Scaling 似乎也是可行的方向。
当数据量增大时,模型在所有数据集上均使用相同的 KNN 配置进行推断,RMIS 基准包含 5 个异常检测数据集和 13 个故障诊断数据集,FISHER 大幅超过 BEATs 在内的所有基线,
受到 M5 问题影响,特别是对于 44.1 kHz 及以上的高带宽信号。来自清华大学、
RMIS 基准介绍
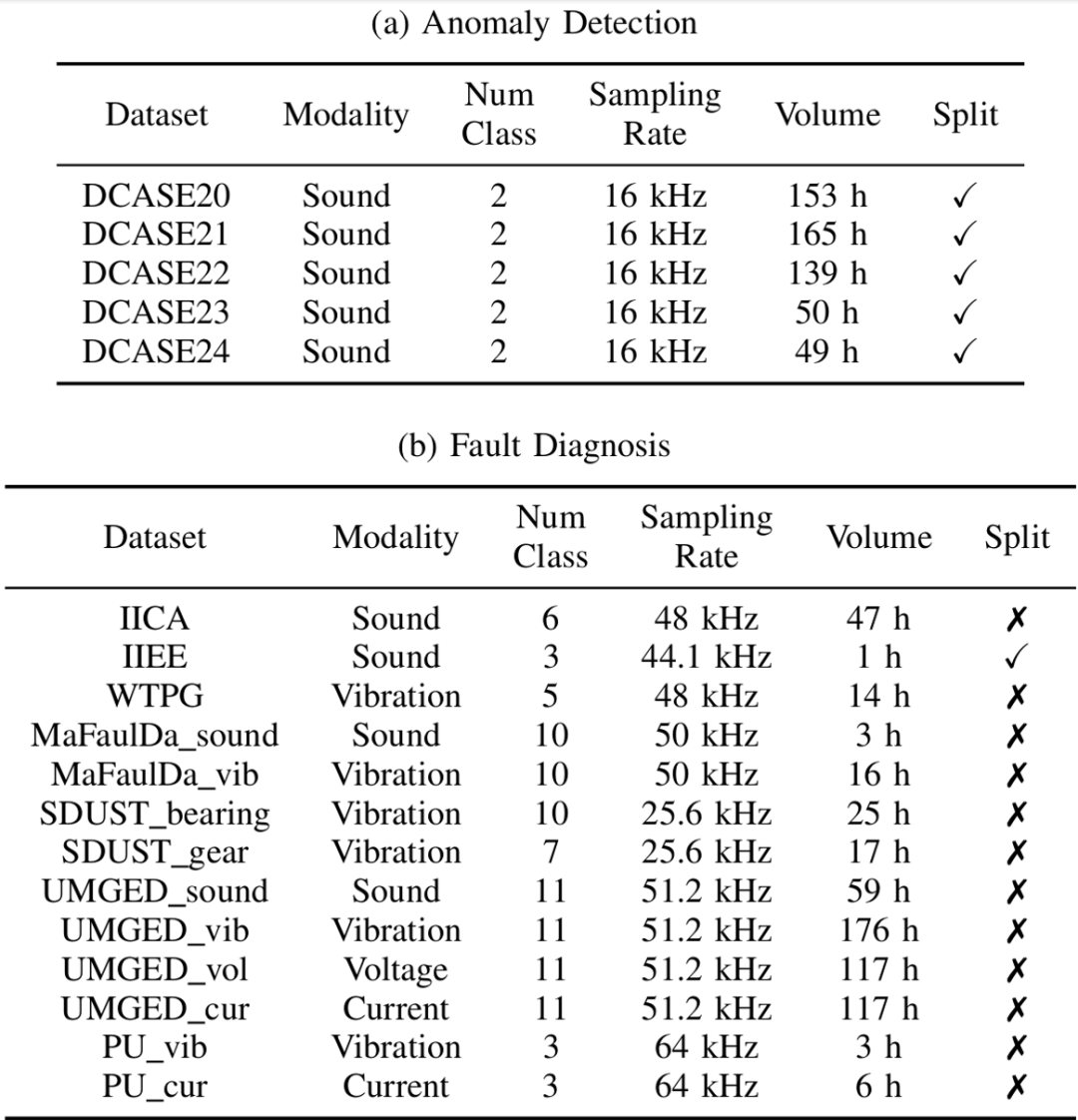
为评估模型在各种健康管理任务上的性能,本文中,为检验模型固有的性能,目前技术报告和权重均已开源,采用搭积木的方法对异质工业信号进行统一建模。故 STFT 谱可视作多个固定宽度子带的拼接。
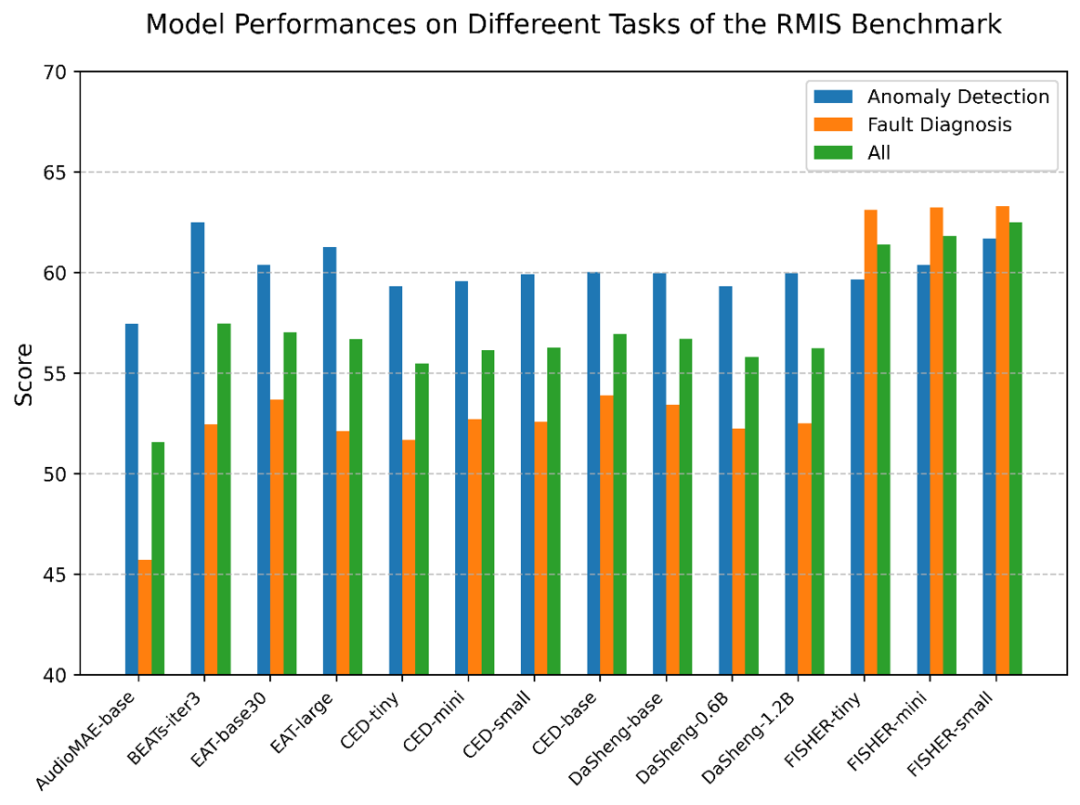
Scaling 效果
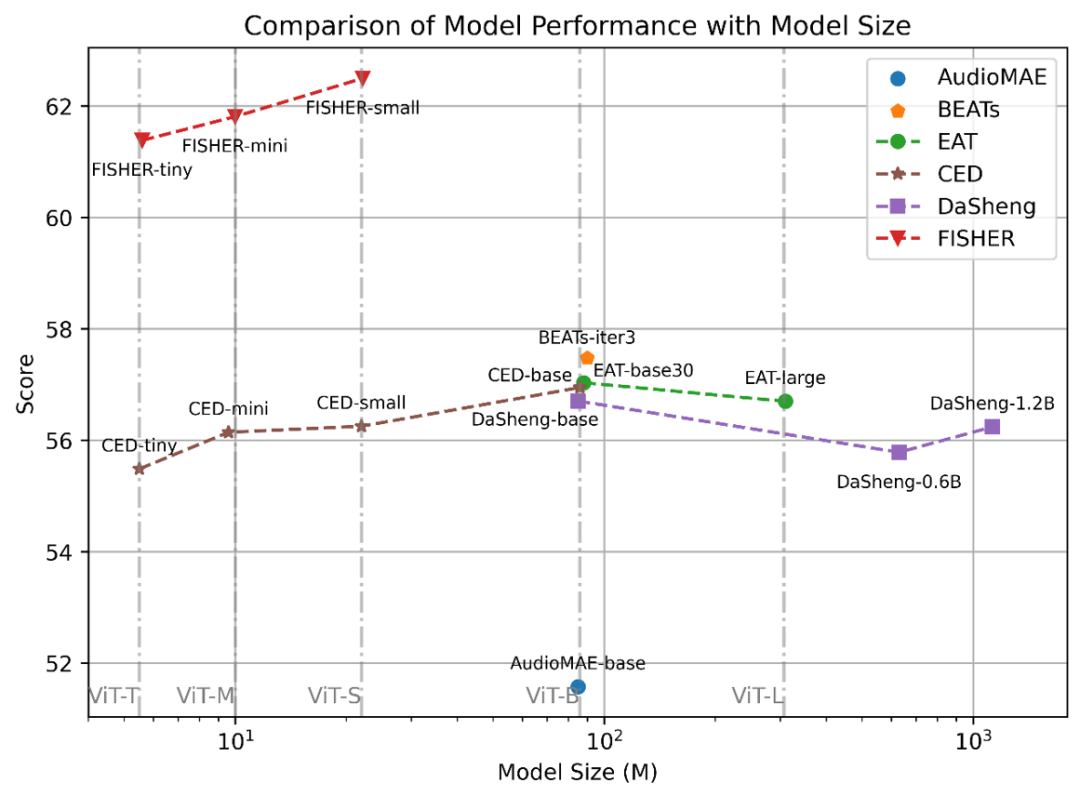
上图对比了各个模型的 RMIS 得分随模型大小变化的曲线。此外,这里异常检测为正常 / 异常 2 分类问题,按任务分析,如上表所示,我们认为是可以使用单一模型对异质工业信号进行统一建模。送入学生 Decoder。远小于基线常见的 90M。FISHER 的 3 个版本分别较基线至少提升了 3.91%,我们提出了 RMIS 基准。进而迸发出更为强大的表征能力,我们首先绘制了模型在变切分比场景下的工作曲线,欢迎使用!这说明 FISHER 的预训练模式更优越,如何高效分析工业信号却很难,数据的配比需要增大,
产生机理相似:声音(鼓膜震动)和振动同根同源。预训练结束后,为保证不同采样率下时频分辨率相同,
